历史背景
| 含义 | 缺点 | |
|---|---|---|
| 进程时代 | 一个程序就是一个进程,所有进程严格按照时间执行 | 进程阻塞十分损耗性能、只能串行执行任务 |
| 线程时代 | 一个进程阻塞,可以切换到其他进程 | 上下文切换成本高、协程内存占用较高 |
| 协程时代 | 协程绑定线程,CPU 调度线程执行 | 实现复杂,协程和线程的绑定依赖调度器算法 |
GMP 调度模型是什么
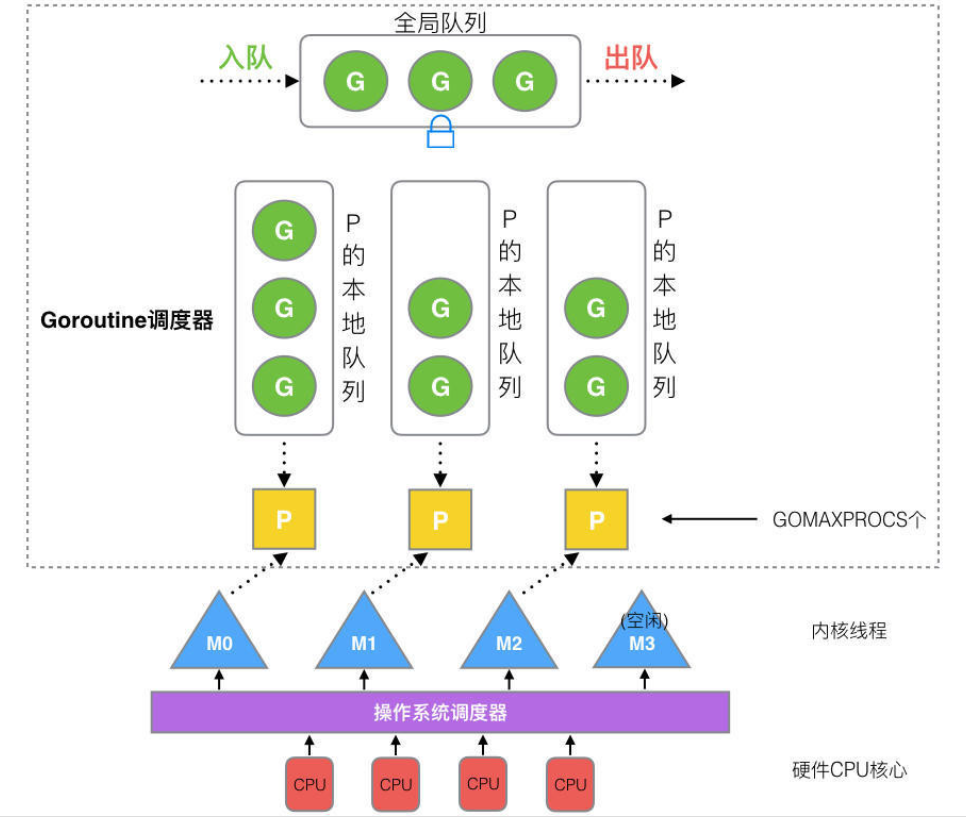
G:Goroutine,是 Go 的用户级线程,每个 go 关键字都会创建一个 Goroutine。其数量理论上只受内存大小影响。
M:Machine,Go 对操作系统线程的封装,M在绑定有效的 P 后,进入一个调度循环,而调度循环的机制大致是从 P 的本地运行队列以及全局队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。M的数量有限制,默认数量限制是 10000,可以通过 debug.SetMaxThreads() 方法进行设置,如果有M空闲,那么就会回收或者睡眠。
P:Processor,虚拟处理器,M执行G所需要的资源和上下文,只有将 P 和 M 绑定,才能让 P 的 runq 中的 G 真正运行起来。P的数量受本机的CPU核数影响,可通过环境变量$GOMAXPROCS或在runtime.GOMAXPROCS()来设置,默认为CPU核心数。
| |
Go 调度原理
调度对象
- G 的来源
- P 的 runnext(1 个 G)
- P 的本地队列(数组,最多 256 个 G)
- 全局 G 队列(链表,G 数量无限制)
- 网络轮询器(存放网络调用阻塞的 G)
- P 的来源
- 全局 P 队列(数组,GOMAXPROCS个P)
- M 的来源
- 休眠线程队列(未绑定 P,长时间休眠会等待GC回收销毁)
- 运行线程(绑定 P,指向 P 中的 G)
- 自旋线程(绑定 P,指向 M 的 G0)
Goroutine 调度流程
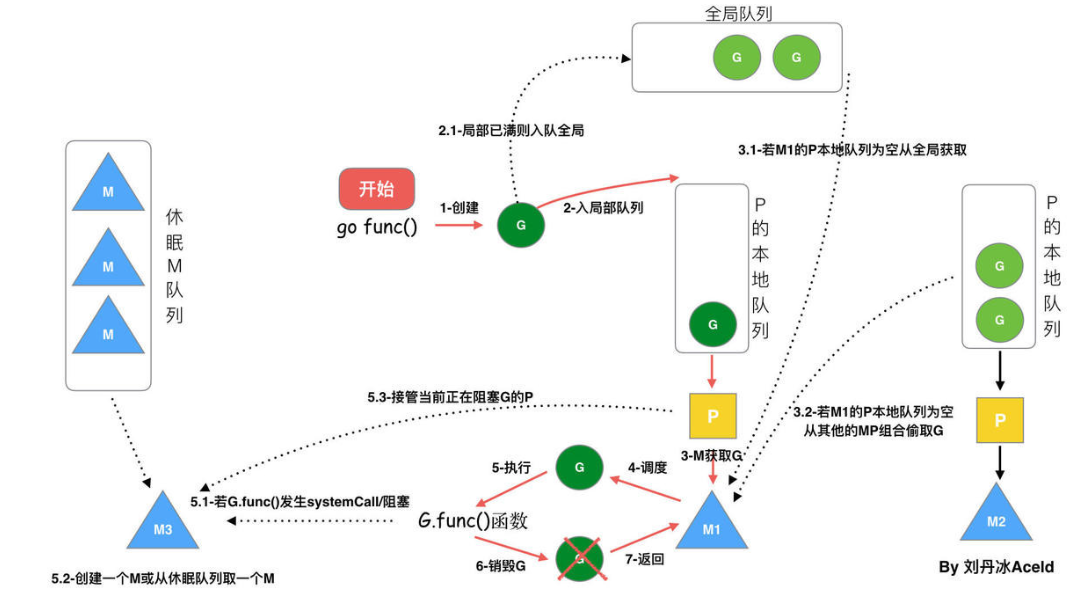
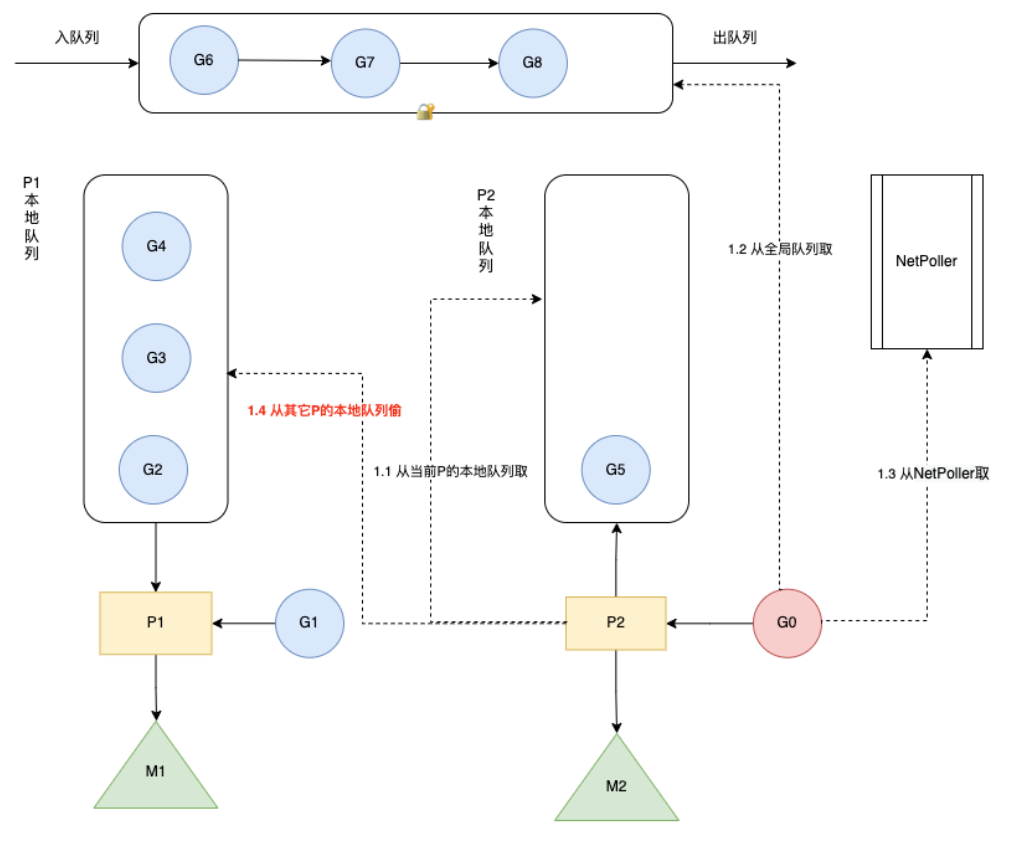
上图是一个完整调度流程:
- 通过 go func() 创建一个 G
- 创建的 G 优先保存到本地队列 P,若本地 P 已满则进去全局队列
- 唤醒或者新建 M 执行任务,进入调度循环(4,5,6)
- M 依次会从本地队列 P,全局队列,其他本地队列 P 获取 G
- M 调度和执行 G
- 如果 M 在执行 G 的过程发生系统调用阻塞(同步),会阻塞 G 和 M(操作系统限制),此时 P 会和当前 M 解绑,并寻找新的 M,如果没有空闲的 M 就会新建一个 M ,接管正在阻塞G所属的P,接着继续执行 P中其余的G,这种阻塞后释放P的方式称之为hand off。当系统调用结束后,这个G会尝试获取一个空闲的P执行,优先获取之前绑定的P,并放入到这个P的本地队列,如果获取不到P,那么这个线程M变成休眠状态,加入到空闲线程中,然后这个G会被放入到全局队列中。
- 如果M在执行G的过程发生网络IO等操作阻塞时(异步),阻塞G,不会阻塞M。M会寻找P中其它可执行的G继续执行,G会被网络轮询器network poller 接手,当阻塞的G恢复后,G1从network poller 被移回到P的 LRQ 中,重新进入可执行状态。异步情况下,通过调度,Go scheduler 成功地将 I/O 的任务转变成了 CPU 任务,或者说将内核级别的线程切换转变成了用户级别的 goroutine 切换,大大提高了效率。
- M 执行完 G 后清理现场,重新进入调度循环(将 M 上运⾏的goroutine切换为G0,G0负责调度时协程的切换)
调度器生命周期
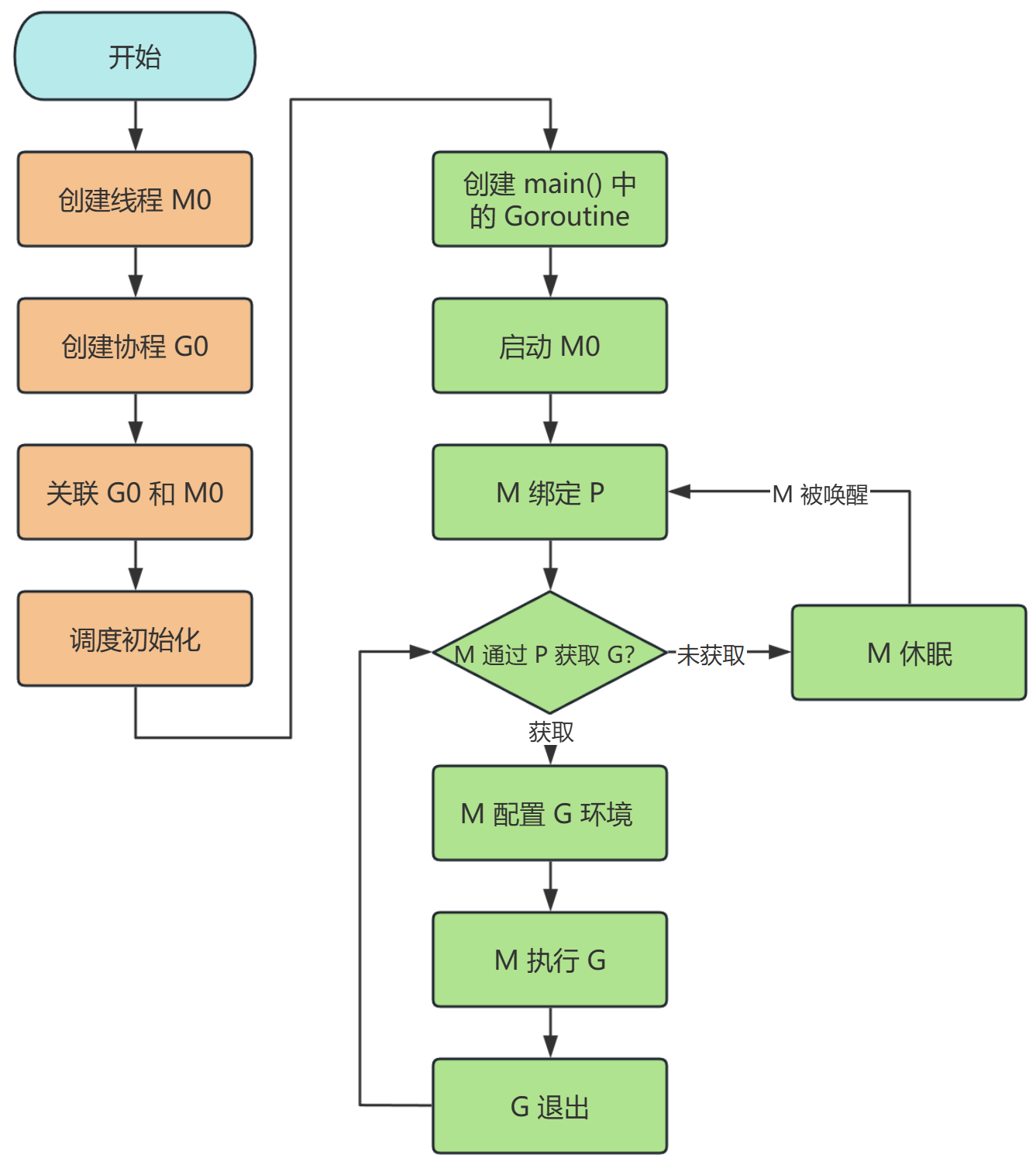
- M0:M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
- G0:G0 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
调度时机
- 抢占式调度
- sysmon检测到协程运行过久(比如sleep,死循环)
- 切换到g0,进入调度循环
- 主动调度
- 新起一个协程和协程执行完毕触发调度循环
- 主动调用runtime.Gosched()切换到g0,进入调度循环
- 垃圾回收之后。stw之后,会重新选择g开始执行
- 被动调度
- 系统调用(比如文件IO)阻塞(同步),阻塞G和M,P与M分离,将P交给其它M绑定,其它M执行P的剩余G
- 网络IO调用阻塞(异步) ,阻塞G,G移动到NetPoller,M执行P的剩余G
- atomic/mutex/channel等阻塞(异步),阻塞G,G移动到channel的等待队列中,M执行P的剩余G
如何挑选下一个执行的 Goroutine
- 每执行61次调度循环,从全局队列获取G,若有则直接返回
- 从P上的runnext看一下是否有G,若有则直接返回
- 从P上的本地队列看一下是否有G,若有则直接返回
- 上面都没查找到时,则去全局队列、网络轮询器查找或者从其他Р中窃取,t一直阻塞直到获取到一个可用 的G为止
netpoller中拿到的G是 _Gwaiting状态(存放的是因为网络IO被阻塞的G),从其它地方拿到的是_Grunnable状态
Goroutine 的调度方式
基于协作的抢占式调度流程(1.2 版本实现)
- 编译器会在调用函数前插入runtime.morestack,让运行时有机会在这段代码中检查是否需要执行抢占 调度
- Go语言运行时会在垃圾回收暂停程序、系统监控发现Goroutine运行超过10ms,那么会在这个协程设置 一个抢占标记
- 当发生函数调用时,可能会执行编译器插入的runtime.morestack,它调用的runtime.newstack会检查抢 占标记,如果有抢占标记就会触发抢占让出cpu,切到调度主协程里
只能局部解决问题,只在有函数调用的地方才能插入“抢占”代码(埋点),对于没有函数调用而是纯算法循环计算的 G,Go 调度器依然无法抢占。
基于信号的抢占式调度(1.14版本实现)
- M注册一个SIGURG信号的处理函数:sighandler
- sysmon启动后会间隔性的进行监控,最长间隔10ms,最短间隔20us。如果发现某协程独占 P超过10ms,会给M发送抢占信号
- M收到信号后,内核执行sighandler函数把当前协程的状态从_Grunning正在执行改成_Grunnable可执 行,把抢占的协程放到全局队列里,M继续寻找其他goroutine来运行
- 被抢占的G再次调度过来执行时,会继续原来的执行流
抢占分为_Prunning和_Psyscall
_Psyscall抢占通常是由于阻塞性系统调用引起的,比如磁盘io、cgo。_Prunning抢占通常是由于一些类似死循环的计算逻辑引起的。
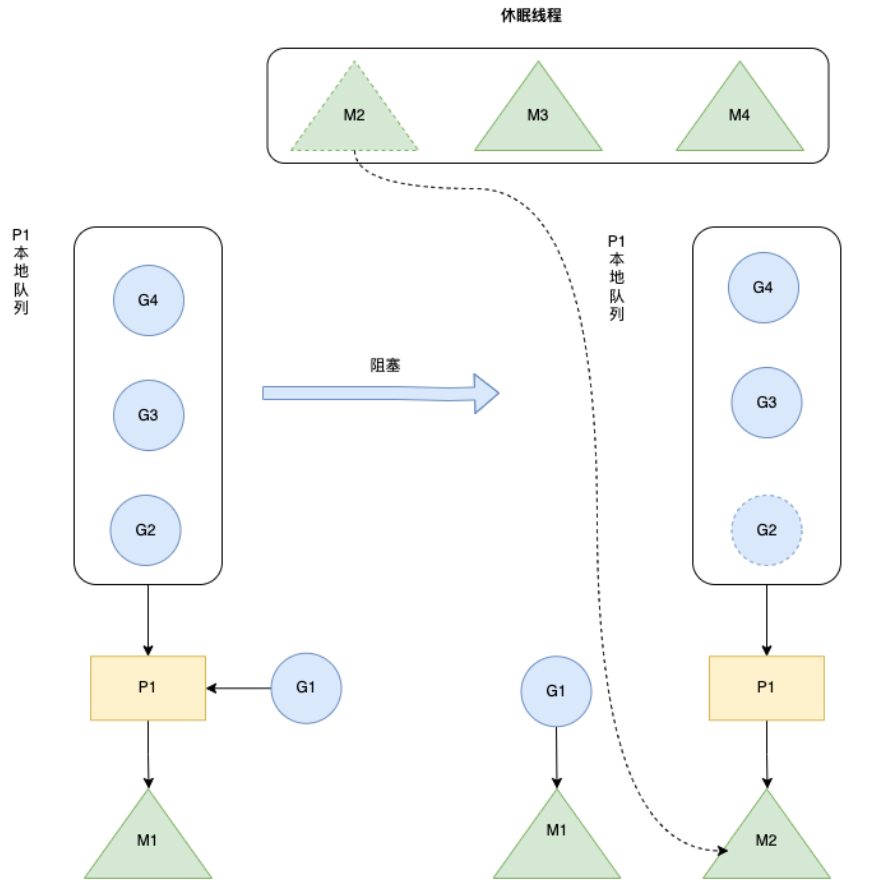
work staeling & hand off
work stealing 机制
当线程M⽆可运⾏的G时,尝试从其他M绑定的 P (每次选择的 P 不一定相同)偷取 G(当前 P 中一半的 G),减少空转,提高了线程利用率。
hand off 机制
也称为 P 分离机制,当线程 M 因为 G 进行的系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的 M 执行,也提高了线程利用率。